1. LLM是如何工作的?
用一句话总结,LLM就是一个”超级猜词机器”。它通过海量文本数据训练,学习语言规律,然后通过概率计算,预测下一个单词。让我们按照处理流程来详细了解LLM的工作原理。
1.1 整体流程图
下面我们先通过流程图来看一下它的工作流程。
graph TD
A[输入文本] --> B(Token化处理)
B --> C{词表示}
C -->|传统方法| C1[One-Hot编码]
C -->|现代方法| C2[动态Embedding]
C2 --> D[+位置编码]
D --> E[Transformer块]
E --> F[自注意力机制]
F --> G[计算词间关联权重]
G --> H[多头注意力拼接]
H --> I[前馈神经网络]
I --> J[LayerNorm]
J --> K{是否最后一层?}
K -->|否| E
K -->|是| L[输出概率分布]
L --> M[温度采样]
M --> N[生成最终Token]
N --> O[输出文本]
style C1 fill:#f9f,stroke:#333,stroke-width:2px
style C2 fill:#8f8,stroke:#333,stroke-width:2px
subgraph 核心迭代
E-->F-->G-->H-->I-->J-->K
end
subgraph 开发者可控参数
B -.-> P[最大Token数]
M -.-> Q[温度值]
L -.-> R[Top-p采样]
end
有了以上的流程图,我们再分步解析
1.2 输入处理:Token化
1.2.1 Token:文字的 “最小零件”
Token是理解大模型的重要概念。是一段文本被切分成的 最小单位 ,比如我们通过openai的分词器 就可以把”ChatGPT is cool!” 这段文字切分为5个token 分别是[“Chat”, “GPT”, “is”, “cool”, “!”]
1.2.2 上下文窗口(Context Window)
各大厂商的竞争中,有一个很重要的指标就是上下文窗口的大小。这里的上下文窗口,指的就是大模型可以处理 Token 数量,上下文越大,能处理的 Token 越多。能处理的 Token 越多,大模型对信息的理解就越充分,生成的内容就越接近我们需要的结果。
下面是 gpt-4o-mini 的上下文窗口处理的 Token 情况(摘自 Open AI 官网)。
同时,token也关系到如何计费。token越多,收费越多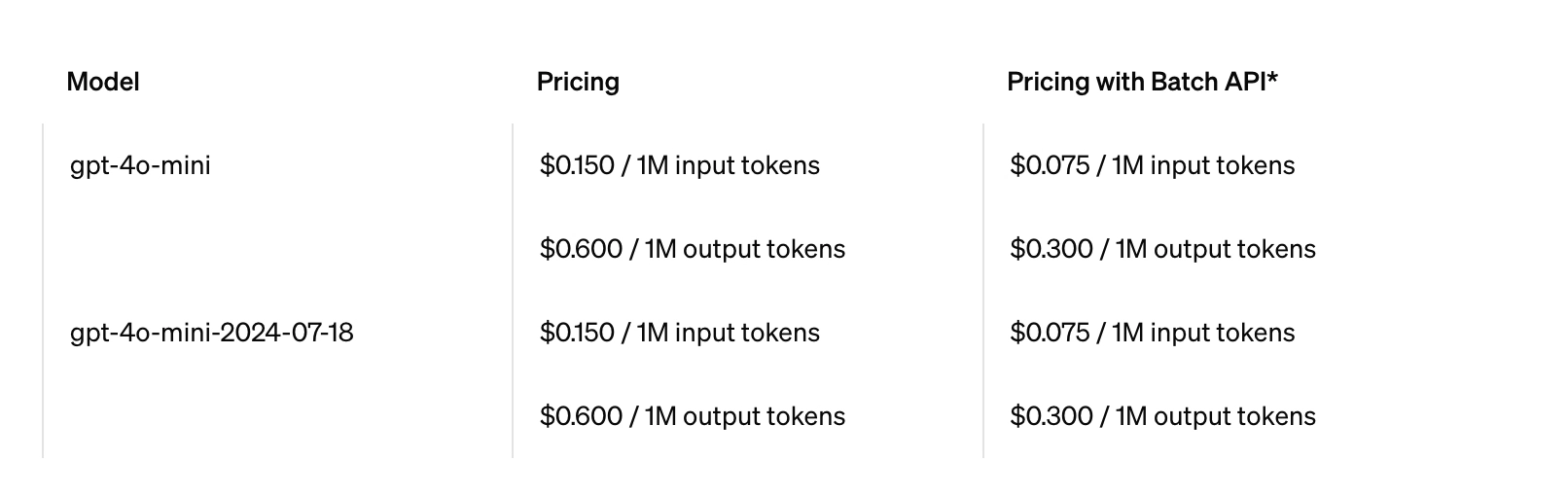
1.3 词表示(Word Representation)
1.3.1 传统方法:One-Hot编码(早期方案)
One-Hot编码是最基础的词表示方法,将每个词表示为一个只有一个1,其余都是0的向量。这种方法简单直观,但无法表达词与词之间的关系。
举个例子,假设我们的词表里只有5个词:[猫, 小猫, 狗, 跑, 睡觉],那么每个词都会被编码成一个5维向量:
// 词表大小为5的One-Hot编码示例
const vocabulary = {
"猫": [1, 0, 0, 0, 0],
"小猫": [0, 1, 0, 0, 0],
"狗": [0, 0, 1, 0, 0],
"跑": [0, 0, 0, 1, 0],
"睡觉": [0, 0, 0, 0, 1]
};
// 虽然"猫"和"小猫"在语义上很接近
// 但它们的One-Hot编码完全不同,无法体现出它们的相似性
const cat = vocabulary["猫"]; // [1, 0, 0, 0, 0]
const kitten = vocabulary["小猫"]; // [0, 1, 0, 0, 0]
// 计算相似度会得到0,说明One-Hot编码无法捕捉词义关系
const similarity = cosineSimilarity(cat, kitten); // 结果为0这个例子展示了One-Hot编码的主要缺点:
- 向量维度随词表大小线性增长(实际词表可能有几万到几十万个词)
- 所有词之间的距离都相等,无法表达词义的相近程度
- 无法进行有意义的向量运算(如类比推理)
1.3.2 现代方法:动态Embedding
Embedding是将字符转换为高维向量(一串数字)的 过程。这种方法不仅能表示词的含义,还能捕捉词之间的关系。
举个例子,假设我们使用300维的向量来表示每个词,那么”猫”这个词可能被表示为:
// 猫的词向量(简化示例,实际是300维)
const cat = [0.2, -0.5, 0.8, 0.1, -0.3, ...]; // 300个数字
// 小猫的词向量
const kitten = [0.18, -0.48, 0.79, 0.12, -0.28, ...]; // 与"猫"的向量非常接近
// 计算相似度(余弦相似度)
const similarity = cosineSimilarity(cat, kitten); // 结果接近1,表示语义相近这种表示方法相比One-Hot编码(假设词表大小为50000,就需要50000维向量)有两个明显优势:
- 维度更低(通常是50~1000维),计算效率更高
- 可以通过向量运算发现词之间的语义关系,比如”猫”和”小猫”的向量距离很近,而”猫”和”狗”的向量距离较远。
1.3.3 位置编码
为了让模型理解词在句子中的位置信息,需要给每个词的Embedding加入位置信息。
1.4 Transformer核心处理
1.4.1 自注意力机制(Self-Attention)
它的核心机制就是让模型处理每个词时,会”注意”其他词的重要性。
比如句子”他打了球,然后它破了”,模型会关联”它”和”球”,而不是”他”。
可以把它想象成代码中的依赖分析:
// 伪代码示例:计算词间关联
function selfAttention(tokens) {
const scores = tokens.map(token =>
tokens.map(other => similarity(token, other))
);
return weightedSum(scores);
}1.4.2 多头注意力机制
通过多个不同的注意力头,模型可以同时关注不同角度的信息,比如语法关系、语义关系等。
1.4.3 前馈神经网络和LayerNorm
经过注意力层后,每个token都会通过一个前馈神经网络进行进一步处理,并通过LayerNorm进行归一化,保持数值稳定。
1.5 输出生成
1.5.1 概率分布
模型会为每个可能的下一个词计算概率。比如输入"今天天气真",模型会计算"好"的概率是80%,"糟糕"的概率是20%,依此类推。
1.5.2 温度采样
在生成内容时,我们通过温度(Temperature)参数来控制输出的随机性(0~1或更高):
- 低温度(如0.2):输出保守、确定性高(适合代码生成)
- 高温度(如0.8):输出更随机、有创意(适合写故事)
示例:
// 低温度 → 输出更集中 → 输出 "2"
model.generate("1+1=", { temperature: 0.2 }); // 输出 "2"
// 高温度 → 可能输出 "2, 或者11?开玩笑的,是2啦!(这都是概率性的结果)"
model.generate("1+1=", { temperature: 0.8 }); // 可能是 "2" 也可能是 "11"1.5.3 Top-p采样
除了温度之外,Top-p采样也是一个重要的控制参数,它决定了模型在选择下一个词时会考虑概率总和达到p的候选词。
假设模型预测下一个词时,好 的概率是0.6,很好的概率是 0.2,非常好的概率是0.1。如果我们设置p=0.8,那么模型只会从好和很好这两个词中选择(因为它们的概率和为0.8),而不会考虑非常好。这种方法可以帮助模型在保持输出质量的同时,避免生成一些低概率(可能不太合适)的词
2. 如何与大模型沟通
我们站在用户视角,写好提示词只需要掌握一个公式:
提示词 = 定义角色 + 背景信息 + 任务目标 + 输出要求
- 定义角色:明确告诉AI它应该扮演什么角色,比如’你是一个资深的前端开发工程师’。这样可以让AI从特定的专业角度思考问题。
- 背景信息:提供必要的上下文信息,如项目背景、技术栈、已有代码等。这些信息能帮助AI更准确地理解问题场景。
- 任务目标:清晰地描述你想要完成什么,可以是具体的编码任务、代码优化、问题诊断等。目标越明确,AI的回答就越精准。
- 输出要求:指定期望的输出格式、代码风格、注释要求等。这能确保AI的回答符合你的具体需求,比如’请用TypeScript实现,并添加详细注释’。
3. 提示工程
3.1 零样本提示(Zero-shot Prompting)
零样本提示是最基础的提示方法,直接告诉模型要做什么,不需要提供示例。
prompt =
优化下面的代码性能:
直接让模型优化代码
function fibonacci(n) {
if (n <= 1) return n;
return fibonacci(n-1) + fibonacci(n-2);
}`;3.2 少样本提示(Few-shot Prompting)
通过提供一些示例来引导模型,让它理解任务模式。
通过示例引导模型进行代码注释
prompt =请按照下面的示例格式为代码添加注释: function add(a, b) { // 接收两个数字参数 return a + b; // 返回它们的和 }
// 需要注释的代码:
function multiply(x, y) {
return x * y;
}`;思维链(Chain-of-Thought)
引导模型一步步思考问题,适合复杂的编程任务。
引导模型逐步思考代码重构
prompt = `请一步步思考如何重构这段代码
思考步骤:
- 首先,分析代码的主要功能
- 找出代码中的重复模式
- 考虑使用现代JavaScript特性
- 提出重构方案
- 实现重构后的代码;
:
function processData(data) {
let result = [];
for(let i = 0; i < data.length; i++) {
if(data[i].type === 'A') {
result.push(data[i].value * 2);
} else if(data[i].type === 'B') {
result.push(data[i].value * 3);
}
}
return result;
}
角色扮演(Role Playing)
让模型扮演特定角色,比如代码审查者、性能优化专家等。
让模型扮演代码审查者
prompt = `你是一个经验丰富的前端代码审查者,请审查下面的React组件代码,重点关注:
- 性能优化
- 最佳实践
- 潜在的内存泄漏
- 代码可维护性
function UserList({ users }) {
const [selectedUser, setSelectedUser] = useState(null);
useEffect(() => {
const handler = () => console.log('window resized');
window.addEventListener('resize', handler);
}, []);
return (
<div>
{users.map(user => (
<div onClick={() => setSelectedUser(user)}>
{user.name}
</div>
))}
</div>
);
}`;这里只提到了基本的几项提示技术,算是抛砖引玉。我们可以通过提示工程指南
4. 衍生
下面这张图展示了基于LLM的几个生态组件(开发框架、RAG、Agent等),仅作抛砖引玉:
- 开发框架 ➔ 上下文管理(记忆与工具集成)
- RAG系统 ➔ 动态知识更新(实时数据注入)
- Agent ➔ 行动反馈(决策优化)
graph TD
A[🤖LLM核心引擎] -->|驱动| B[🛠开发框架(LangChain等)]
A -->|增强| C[🔍RAG系统]
A -->|赋能| D[⚡Agent(智能代理)]
B -->|构建| E[企业级应用]
C -->|支持| E
D -->|实现| E
B -->|集成| F[工具链]
D -->|调用| F
C -->|依赖| G[数据基础设施]
G -->|包含| G1[向量数据库]
G -->|包含| G2[知识图谱]
F -->|包含| F1[API服务]
F -->|包含| F2[代码执行]
F -->|包含| F3[硬件控制]
subgraph 核心循环
A <-->|上下文交互| B
A <-->|知识更新| C
A <-->|动作反馈| D
end
subgraph 应用场景
E --> E1[智能客服]
E --> E2[数据分析]
E --> E3[流程自动化]
end

